Como validar a latência da inferência de IA

Identifique os limites de latência com antecedência
Validar a latência da inferência em inteligência artificial (IA) é um desafio, pois as implantações em produção precisam processar usuários simultâneos, prompts com contexto extenso e conversas com várias trocas de mensagens ao mesmo tempo, em vez de solicitações isoladas de benchmark. Essas condições de carga de trabalho podem aumentar a latência de resposta, reduzir a taxa de processamento, causar a perda ou o atraso de solicitações e resultar em uma utilização desigual dos recursos da unidade de processamento gráfico (GPU) nas diferentes etapas do pipeline de inferência, tornando difícil prever o desempenho no mundo real apenas com base em testes sintéticos.
Uma validação eficaz da latência de inferência de IA requer uma emulação de carga de trabalho repetível que reflita o comportamento realista das solicitações, a simultaneidade de usuários e os padrões de resposta, ao mesmo tempo em que mede o desempenho sensível ao tempo em toda a pilha. Os engenheiros precisam de visibilidade sobre métricas como tempo até o primeiro token, tempo até o último token, tokens por segundo, utilização do cache e telemetria da GPU para que possam identificar gargalos, avaliar limites de escalabilidade e compreender como as escolhas de projeto da infraestrutura afetam a experiência do usuário em condições semelhantes às de produção.

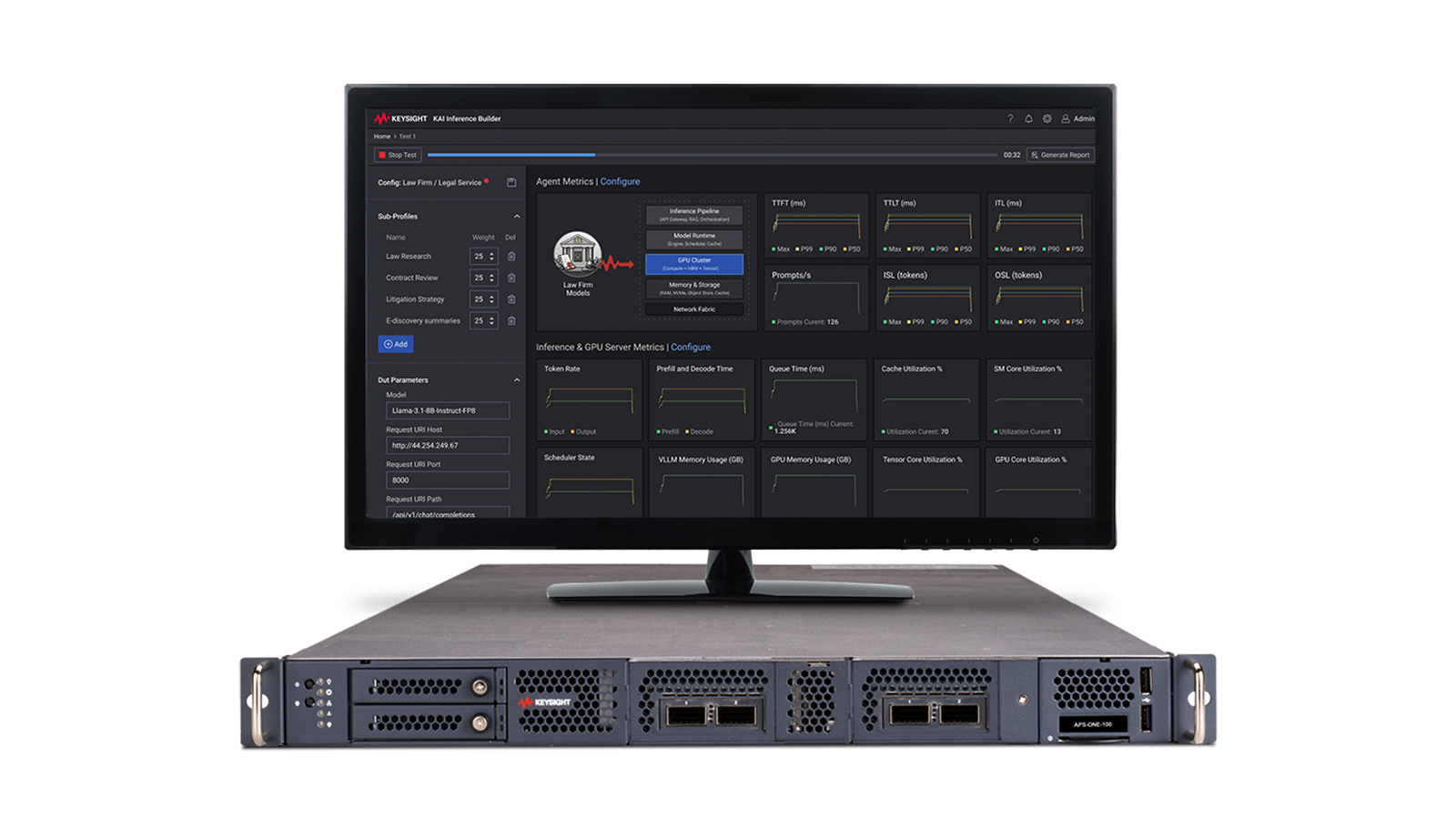
Solução para a latência na inferência de IA
Veja o diagrama de blocos da solução para latência de inferência de IA


Conheça os produtos para a solução de latência de inferência de IA
-

![]()
Pacote KAI Inference Builder 952-1100 com 10 agentes e até 10.000 solicitações por segundo
-
![]()
Pacote KAI Inference Builder 952-1010 com 10 agentes e até 1.000 solicitações por segundo
-
![]()
Pacote KAI Inference Builder 952-1001 com 2 agentes e até 100 solicitações por segundo


Descubra recursos e percepções
Recursos adicionais para a solução de latência de inferência de IA
Casos de uso relacionados



-
![]()
Saiba mais
Como validar interconexões Ethernet em data centers
A validação de interconexões Ethernet em data centers exige testes precisos de confiabilidade e desempenho. Saiba como garantir a transmissão de dados de alta qualidade e a correção de erros.
Saiba mais

-
![]()
Saiba mais
Como emular cargas de trabalho do data center de IA
A emulação de cargas de trabalho de data center de IA requer uma metodologia de teste consistente, repetível e dimensionável. Saiba como otimizar a infraestrutura para o desempenho do treinamento em IA.
Saiba mais
-
![]()
Saiba mais
Como validar a interoperabilidade e a resiliência de link em redes 800GE
Validar a interoperabilidade 800GE, o comportamento da correção de erros de transmissão, a taxa de transferência e a resiliência do link em interconexões Ethernet ópticas e de cobre para redes de IA e de data center.
Saiba mais

Entre em contato com um de nossos especialistas
Precisa de ajuda para encontrar a solução certa para você?