Comment évaluer la latence de l'inférence IA

Identifier rapidement les limites de latence
La validation de la latence d'inférence de l'intelligence artificielle (IA) est un véritable défi, car les déploiements en production doivent traiter simultanément des utilisateurs en parallèle, des requêtes à contexte étendu et des conversations à plusieurs tours, contrairement aux requêtes de benchmark isolées. Ces conditions de charge de travail peuvent accroître la latence de réponse, réduire le débit, entraîner des requêtes perdues ou retardées, et se traduire par une utilisation inégale des ressources des processeurs graphiques (GPU) à travers les différentes étapes du pipeline d'inférence, rendant ainsi difficile la prévision des performances réelles à partir de tests synthétiques seuls.
Pour valider efficacement la latence des inférences IA, il est nécessaire de disposer d'une émulation de charge de travail reproductible qui reflète le comportement réel des requêtes, la concurrence entre les utilisateurs et les schémas de réponse, tout en mesurant les performances sensibles au temps sur l'ensemble de la pile. Les ingénieurs doivent disposer d'une visibilité sur des indicateurs tels que le temps jusqu'au premier token, le temps jusqu'au dernier token, le nombre de tokens par seconde, l'utilisation du cache et la télémétrie GPU afin de pouvoir identifier les goulots d'étranglement, évaluer les limites d'évolutivité et comprendre comment les choix de conception de l'infrastructure affectent l'expérience utilisateur dans des conditions proches de celles de la production.

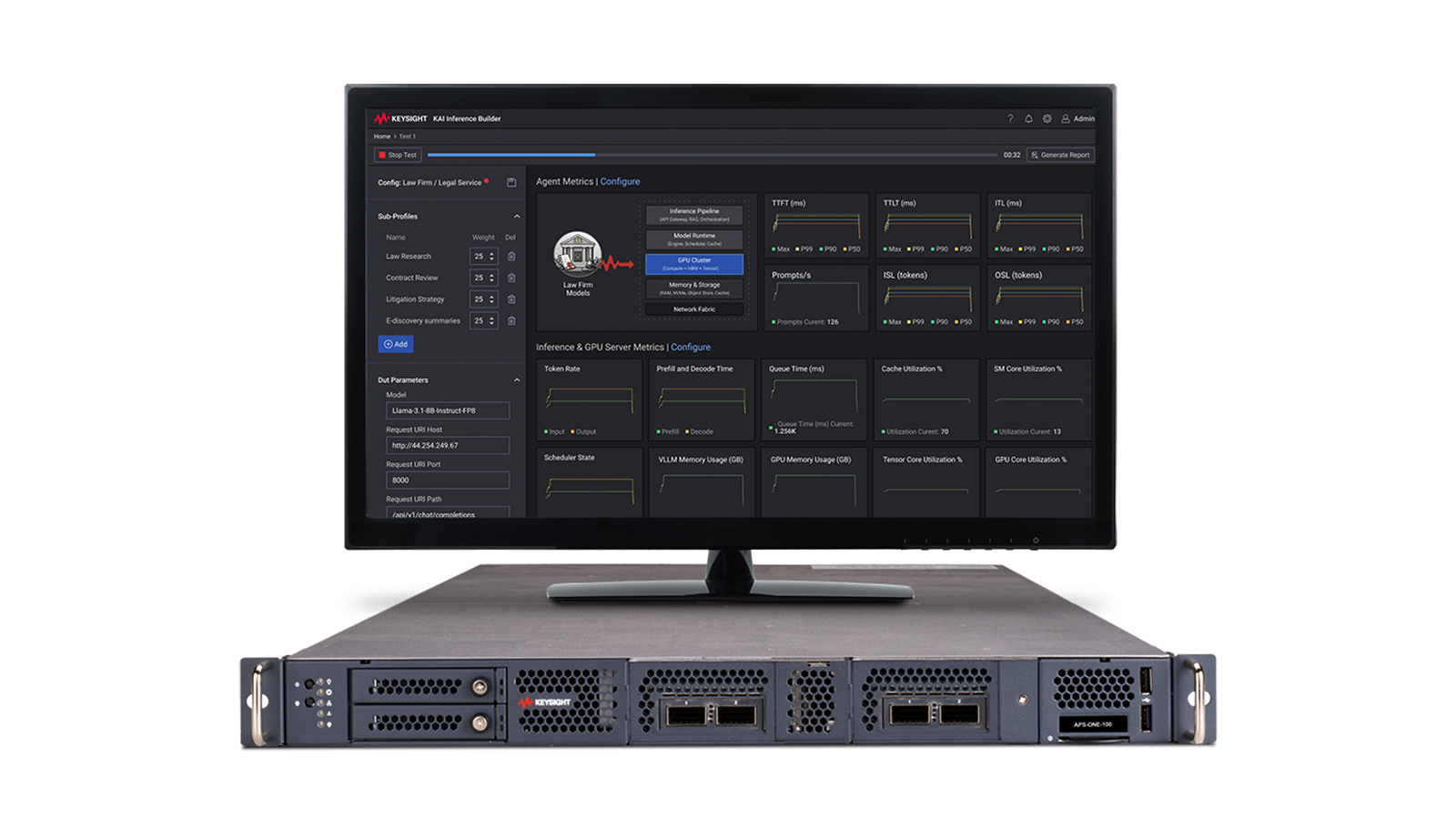
Solution pour réduire la latence de l'inférence IA
Voir le schéma fonctionnel de la solution de réduction de la latence en inférence IA


Découvrez nos produits pour réduire la latence dans l'inférence IA
-

![]()
952-1100 KAI Inference Builder : offre groupée comprenant 10 agents et jusqu'à 10 000 requêtes par seconde
-
![]()
952-1010 Pack KAI Inference Builder comprenant 10 agents et jusqu'à 1 000 requêtes par seconde
-
![]()
952-1001 Pack KAI Inference Builder comprenant 2 agents et jusqu'à 100 requêtes par seconde


Découvrir les ressources et les idées
Ressources supplémentaires sur les solutions de réduction de la latence en inférence IA
Cas d'utilisation connexes



-
![]()
En savoir plus
Comment vérifier l'interopérabilité 800GE et la résilience des liaisons
Valider l'interopérabilité 800GE, le comportement de la correction d'erreurs sans perte, le débit et la résilience des liaisons sur les interconnexions Ethernet optiques et cuivre pour les réseaux d'IA et de centres de données.
En savoir plus

-
![]()
En savoir plus
Comment tester les structures Ethernet IA 1,6 T
Validez les infrastructures d'IA basées sur Ethernet à l'aide de tests réalistes portant sur le trafic de formation, la congestion, la latence et l'évolutivité.
En savoir plus
-
![]()
En savoir plus
Comment évaluer la congestion du réseau AI Fabric
Simulez un trafic de formation de l'IA par rafales afin d'identifier les points de congestion, la latence résiduelle et les limites de débit avant de déployer l'infrastructure du centre de données dédié à l'IA.
En savoir plus

Contactez l'un de nos experts
Besoin d'aide pour trouver la solution qui vous convient ?