Che cosa sta cercando?
Reti AI
Massimizzare le prestazioni dei data center AI.
Ottimizzare le prestazioni e l'efficienza della rete AI
Accelerate le implementazioni di data center AI, convalidate le prestazioni di SmartNIC e testate i componenti di rete. Utilizzate emulatori di traffico reali per monitorare in tempo reale una serie di metriche AI standard del settore, come il tempo di completamento dei lavori e la larghezza di banda delle comunicazioni collettive. Eseguite il benchmark delle prestazioni della rete AI, individuate i colli di bottiglia e ottimizzate la distribuzione del carico di lavoro AI con strumenti di test della rete ottimizzati per l'AI, tra cui emulatori di carichi di lavoro AI, generatori di traffico di rete distribuito ed emulatori di traffico di rete.
Tutto quello che c'è da sapere sulle reti di intelligenza artificiale


Juniper costruisce reti AI di prossima generazione con Keysight
Scoprite come Juniper Networks ha collaborato con Keysight per realizzare l'infrastruttura di rete per le reti AI. Scoprite come gli strumenti di emulazione di rete di Keysight hanno aiutato Juniper a testare e convalidare i propri prodotti rispetto alle esigenze reali dei data center AI.


5 strategie per ottimizzare e scalare i data center AI
L'intelligenza artificiale sta trasformando i settori e guidando l'innovazione. Tuttavia, modelli di traffico unici, carichi di lavoro dinamici e pressioni incessanti sulle prestazioni possono trasformare anche i problemi più piccoli in problemi critici.
Leggete questo eBook per scoprire cinque soluzioni pratiche per ottimizzare le prestazioni dei data center AI per le applicazioni moderne.


Miglioramento della scalabilità nei cluster di data center AI
La vostra infrastruttura di rete è in grado di gestire carichi di lavoro complessi e ad alto traffico per l'addestramento all'intelligenza artificiale? Questo white paper approfondisce il tema della scalabilità dei cluster dei data center AI, identifica le sfide critiche della rete e spiega come garantire reti scalabili e affidabili per le ambizioni AI della vostra organizzazione.
Bootcamp di rete AI
Unisciti agli ingegneri Keysight per un'immersione profonda nel mondo dei test delle reti AI e della convalida delle implementazioni dei data center AI. Al termine di questo corso, otterrete le conoscenze e la sicurezza necessarie per assumere il controllo di questo nuovo paradigma di rete innovativo e in rapida evoluzione.


Benchmarking delle operazioni collettive
La misurazione o il benchmarking delle prestazioni della rete in un cluster di IA può aiutare le organizzazioni a identificare le opportunità di ottimizzazione e miglioramento del throughput complessivo senza costi hardware aggiuntivi. Questo white paper spiega il funzionamento dei collettivi di IA, definisce la terminologia e passa in rassegna le metriche più comuni associate al benchmarking delle reti di IA.
Validazione di Ethernet senza perdite a velocità fino a 1,6T
Rimanete al passo con l'accelerazione della domanda di prestazioni garantendo una trasmissione affidabile dei dati nelle reti di AI/ML e di calcolo ad alte prestazioni.
Test a pressione delle apparecchiature di rete AI con emulazioni di carichi di lavoro AI
Riducete la necessità di costose configurazioni di laboratorio basate su GPU con generatori di traffico ad alta densità che emulano il comportamento dei carichi di lavoro dell'intelligenza artificiale per ottimizzare le prestazioni e l'efficienza.
Scoprite come i parametri di rete specifici dell'AI influiscono sulle prestazioni
Scegliete tra una serie di modelli di traffico e profili di carico di lavoro per semplificare il benchmarking e testare le prestazioni della rete a livello di componente e di sistema.
Esplora le soluzioni per le reti AI


Ottimizzare l'infrastruttura AI con KAI Data Center Builder
Eseguite il benchmark delle prestazioni dei data center di intelligenza artificiale con una fedeltà senza precedenti. KAI Data Center Builder emula la combinazione di comunicazioni collettive e algoritmi utilizzati per costruire un modello di apprendimento di grandi dimensioni (LLM), facilitando la convalida dell'infrastruttura di rete e dei tessuti di IA tramite test a livello di sistema.


Massimizzare l'affidabilità e le prestazioni di Ethernet 1.6T
Testate prodotti Ethernet all'avanguardia per interconnessioni AI e reti di data center. Con il supporto per i test di livello fisico (L1) e di protocollo (L2-3), il Keysight Interconnect and Network Performance Tester 1600GE offre una copertura di test ineguagliabile per le interconnessioni ottiche e a cavo attivo, gli switch di rete e le reti AI.
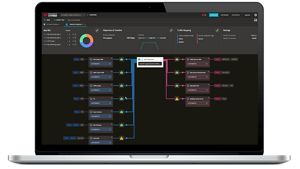

Validazione delle SmartNIC e dell'infrastruttura LLM con CyPerf
Testate le apparecchiature di rete ad alte prestazioni con emulazioni di traffico e scenari di test ad alta intensità di calcolo e nativi dell'intelligenza artificiale. Keysight CyPerf semplifica la valutazione delle prestazioni, della scalabilità e della stabilità del sistema attraverso il benchmarking, la simulazione del traffico reale e i test su larga scala.
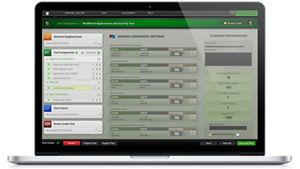

Proteggere gli LLM dagli attacchi avanzati con BreakingPoint
Proteggete i modelli linguistici di grandi dimensioni dal tipo di cyberattacco più diffuso che colpisce le reti di intelligenza artificiale: i prompt injection strikes. BreakingPoint di Keysight è uno strumento avanzato di sicurezza di rete e di test delle applicazioni, in grado di convalidare la sicurezza, la stabilità e le prestazioni delle reti AI e delle apparecchiature di rete che le alimentano.
Prospettiva dei dirigenti: Soluzioni AI di Keysight
Ram Periakaruppan, vicepresidente e direttore generale della divisione Network Applications and Security di Keysight Technologies, ha parlato delle principali sfide che i data center AI devono affrontare, di come ottimizzare le prestazioni e l'efficienza dell'AI e di come Keysight sta aiutando con il portafoglio di soluzioni AI per data center.
Setup di test per la validazione delle reti di intelligenza artificiale
Reti di centri dati AI di prova
Emulazione di carichi di lavoro AI per eseguire il benchmark delle apparecchiature di rete e convalidare i tessuti AI/ML.


Convalida delle interconnessioni Ethernet
Garantire una trasmissione dei dati e una correzione degli errori di alta qualità, verificando l'affidabilità e le prestazioni.
Emulazione dei carichi di lavoro del centro dati AI
Ottimizzare l'infrastruttura per le prestazioni di formazione dell'intelligenza artificiale con una metodologia di test coerente e scalabile.
Per saperne di più sulle reti AI














Domande frequenti: Reti AI
In una rete tradizionale, il tipo e la dimensione del carico di lavoro variano, il traffico è distribuito su diverse connessioni, cresce proporzionalmente al numero di utenti e i pacchetti in ritardo o caduti non causano in genere problemi significativi. In una rete di intelligenza artificiale, le GPU lavorano tutte sullo stesso problema, la costruzione di un modello linguistico di grandi dimensioni (LLM). I carichi di lavoro per la creazione di un LLM richiedono la condivisione di enormi quantità di dati tra le GPU, senza che i pacchetti cadano o si verifichino congestioni. Poiché le GPU lavorano tutte sullo stesso problema, completano un'attività quando l'ultima GPU termina l'elaborazione. Qualsiasi ritardo nella consegna dei dati a una GPU comporta un ritardo dell'intero carico di lavoro.
L'ottimizzazione di una rete di intelligenza artificiale è diversa dall'ottimizzazione di una rete di data center tradizionale. Le reti di intelligenza artificiale funzionano quasi a pieno regime e devono essere prive di perdite per massimizzare l'utilizzo delle GPU. Sono disponibili diversi meccanismi di congestione con varie impostazioni. L'esecuzione di carichi di lavoro di IA in laboratorio con strumenti di benchmarking fornisce un percorso per trovare le configurazioni e le impostazioni ottimali che possono poi essere applicate agli ambienti di produzione.
In una rete di intelligenza artificiale, le GPU lavorano sullo stesso problema, completando un'attività solo quando l'ultima GPU riceve i dati necessari e termina l'elaborazione. Una delle misure chiave delle prestazioni di una rete di intelligenza artificiale è la latenza di coda, ossia i flussi con i tempi di completamento più lunghi. La misura è chiamata P95, ovvero il tempo di completamento del cinque per cento più lento dei flussi di rete.
RDMA è un acronimo che sta per Remote Direct Memory Access. RDMA consente alle GPU di trasferire i dati tra loro in un data center AI con un coinvolgimento minimo della CPU e degli stack di rete. Ciò consente comunicazioni a bassa latenza e ad alta velocità in un data center AI. Le schede di interfaccia di rete abilitate per RDMA in un server si collegano agli switch abilitati per RDMA per consentire la comunicazione ad alta velocità tra le GPU.
Ultra Ethernet (UE) aggiunge funzionalità a Ethernet per fornire una rete veloce, altamente scalabile e a bassa latenza per i requisiti di AI e di calcolo ad alte prestazioni. Il packet spraying permette ai flussi di utilizzare più di un percorso verso una destinazione, consentendo un migliore bilanciamento del carico sulla rete. L'ordinamento flessibile consente ai pacchetti di arrivare a destinazione anche in ordine sparso. Il controllo della congestione basato sul ricevitore si basa sui meccanismi di controllo della congestione esistenti basati sul mittente per migliorare la congestione in-cast che si verifica con i collettivi AI come All-to-All. Il miglioramento della telemetria consente di accelerare i tempi di segnalazione del piano di controllo, migliorando la risposta agli eventi di congestione. L'UE è interoperabile con gli switch Ethernet dei data center esistenti, ma funzionerà in modo più efficiente - con un maggiore utilizzo della rete e una latenza di coda ridotta - utilizzando switch e schede di interfaccia di rete basati su UEC.
Lo spostamento dei dati tra le GPU è chiamato operazione collettiva. Ne esistono diversi tipi, a seconda della posizione iniziale e finale dei dati e della necessità di eseguire un'esecuzione matematica sui dati durante il processo. I tipi comunemente usati sono Broadcast and Gather, ReduceScatter, AllGather, AllReduce e AlltoAll. La presenza della parola chiave "reduce" nel nome dell'operazione indica che questa operazione esegue calcoli sui dati. Un'operazione collettiva può essere implementata utilizzando un numero qualsiasi di algoritmi. Gli algoritmi più noti per AllReduce sono Unidirectional e Bidirectional Ring, Double Binary Tree e Halving-Doubling. Ognuno di essi dimostra prestazioni migliori o peggiori a seconda del numero di GPU e del modo in cui sono interconnesse.
Volete aiuto o avete domande?