Wir denken, das dies die Seite ist, die Sie sehen wollten.
Stattdessen Suchergebnisse ansehen:
Choose a country or area to see content specific to your location
Können wir Ihnen behilflich sein?
Empfohlene Suchanfragen
No product matches found - System Exception
Passende Inhalte
-
-
WirelessPro 3GPP KI-Simulationsplattform
WirelessPro ermöglicht es Ihnen, verschiedene Aspekte von 5G-Netzwerken zu modellieren, zu simulieren und zu analysieren. Advanced Technologien und zukünftige 6G-Funkkanäle mit beispielloser Leichtigkeit und Genauigkeit.


-
Digitale Validierung. Schneller.
Erhalten Sie schnellere und klarere Erkenntnisse mit unserem neuen Multicore-12-Bit-Oszilloskop mit bis zu 33 GHz.

-
Entdecken Sie den Keysight AI Data Center Builder
Simulieren Sie jeden Teil Ihrer Rechenzentrumsinfrastruktur. Simulieren Sie alles. Optimieren Sie alles.

-
Komplexität vereinfachen mit Advanced Signalanalysesoftware
Beschleunigen Sie die Signalanalyse mit der VSA-Software von Keysight. Visualisieren, demodulieren und beheben Sie Fehler mit über 75 Signalstandards präzise.

-
Einführung KI-gestützter Paketbroker
Mit zusätzlichem Speicher und Speicherplatz können diese verbesserten NPBs die KI-Sicherheits- und Leistungsüberwachungssoftware sowie den KI-Stack von Keysight ausführen.

-
Präzisionsprüfung im laufenden Betrieb für die Produktion
Erreichen Sie schnelle und präzise Tests auf Platinenebene mit robusten Inline- und Offline-ICT-Systemen, die für die moderne Fertigung entwickelt wurden.

-
Beschleunigen Sie Ihren Innovationsmotor
Informieren Sie sich über kuratierte Support-Pläne, die nach Prioritäten geordnet sind, um Ihre Innovationsgeschwindigkeit aufrechtzuerhalten.

-
-
Streamen Sie 120-MHz-I/Q-Daten direkt im Feld auf Ihren Laptop.Punktgenaue Störungen mit der Nachbearbeitungssoftware für das Spektrummanagement im Labor.
 Jetzt können Sie schnelle und präzise Tests bis zu 192 kW durchführen.
Jetzt können Sie schnelle und präzise Tests bis zu 192 kW durchführen.Unsere hochdichten ATE-Netzteile beseitigen den Zielkonflikt zwischen Testdurchsatz und Präzision.

-
- Lösungen
-
Entdecken Sie von Ingenieuren verfasste Inhalte und eine umfangreiche Wissensdatenbank mit Tausenden von Lernmöglichkeiten.
AusgewähltKeysight Learn bietet umfassende Inhalte zu interessanten Themen, darunter Lösungen, Blogs, Veranstaltungen und mehr.
Mein Lern-DashboardVerfolgen. Entdecken. Personalisieren.
Alles an einem Ort. -
Schneller Zugriff auf die häufigsten unterstützungsbezogenen Selbsthilfeaufgaben.
Zusätzliche Inhalte zur Unterstützung Ihrer Produktanforderungen.
Mehr erreichen mit Keysight ServicesEntdecken Sie Dienstleistungen, die jeden Schritt Ihrer Innovationsreise beschleunigen.








SPRACHE
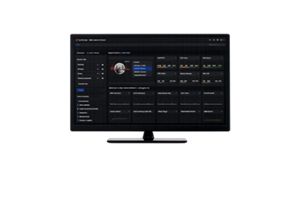
KAI Inference Builder: KI-Inferenzinfrastrukturen validieren und optimieren
Modell: 952-1010
vorher
- Überblick
- Optionen
- Zubehör
- Software
- Unterstützung
KAI Inference Builder Bundle mit 10 Agenten und bis zu 1000 Eingabeaufforderungen pro Sekunde
Das KAI Inference Builder Bundle umfasst 10 Agenten und bis zu 1000 Eingabeaufforderungen pro Sekunde (1-Jahres-Abonnement, weltweit gültig). Das Bundle ist TAA-konform.

-
Form factor
Software
-
License types
Subscription
-
Performance Level
1000 prompts per second, 10000 simulated users

Bereit für ein Angebot?
Erfahren Sie, was alles enthalten ist und welche Upgrade-Optionen von Keysight verfügbar sind.
Highlights
- Realistisches KI-Clientverhalten in großem Umfang emulieren, um ganze KI-Inferenzinfrastrukturen und -Stacks zu validieren.
- Wählen Sie verschiedene KI-Persona-Aufforderungen, die Druckpunkte in verschiedenen Phasen der KI-Inferenzpipeline auslösen.
- Validierung von KI-Inferenzinfrastrukturen, die in öffentlichen oder privaten Clouds eingesetzt werden, mit vollständig virtueller oder hardwarebasierter Inferenzclient-Emulation.
- Skalieren Sie auf Millionen von simulierten Benutzern mit detaillierter Kontrolle über die generierten Eingabeaufforderungen pro Sekunde für unübertroffene Skalierungstests von KI-Inferenz.
- Erhalten Sie detaillierte Inferenzstatistiken, um umsetzbare Erkenntnisse über potenzielle Engpässe, Grenzen und Ineffizienzen in verschiedenen Komponenten der KI-Inferenzpipeline zu gewinnen:
- GPU-Berechnung
- HBM / VRAM Speichersysteme
- KV-Cache- und Speicherschichten
- PCIe- und RDMA-Verbindungen
- Modell-Engines und Orchestratoren
- Korrelation von clientseitigen Metriken mit der Erfassung von Telemetriedaten auf Inferenzmaschinenebene (z. B. VLLM-Statistiken) und GPU-Telemetriedaten auf Systemebene (z. B. DCGM-Daten) in einer einzigen zeitlich synchronisierten Ansicht:
- Eingabeaufforderungen ser second
- Gleichzeitige Benutzer
- Zeit bis zum ersten Token (TTFT) — Maximalwert und Perzentile (z. B. P50, P90, P99)
- Zeit bis zum letzten Token (TTLT) — Maximalwert und Perzentile (z. B. P50, P90, P99)
- Token pro Sekunde (Ein-/Ausgabe)
- Cache-Nutzung
- Vorfüll- und Dekodierungszeit
- Tensor Core-Nutzung
- Planerstatus
- GPU-Leistungsaufnahme
Dienstleistungen und Support
Innovieren Sie im Handumdrehen mit maßgeschneiderten Supportplänen und priorisierten Reaktions- und Bearbeitungszeiten.
Profitieren Sie von planbaren, leasingbasierten Abonnements und umfassenden Lifecycle-Management-Lösungen – damit Sie Ihre Geschäftsziele schneller erreichen.
Als KeysightCare-Abonnent profitieren Sie von einem erweiterten Service mit zuverlässiger technischer Unterstützung und vielem mehr.
Stellen Sie sicher, dass Ihr Testsystem den Spezifikationen entspricht und sowohl lokale als auch globale Standards erfüllt.
Schnelle Messungen dank hauseigener, von Ausbildern geleiteter Schulungen und E-Learning.
Laden Sie die Keysight-Software herunter oder aktualisieren Sie Ihre Software auf die neueste Version.
Beginnen Sie Ihr Angebot mit der Auswahl eines Produkts
Konfiguration auswählen